NVIDIA A100 Tensor Core GPU
Die beste Beschleunigung für Ihr Rechenzentrum
Die NVIDIA A100 Tensor Core-GPU dient mit einer nie dagewesenen Beschleunigung als Grundlage für die leistungsstärksten elastischen Rechenzentren in den Bereichen KI, Datenanalyse und HPC.
Nutzen Sie die neueste NVIDIA Ampere-Architektur mit einer bis zu 20-mal höheren Leistung gegenüber Vorgängergenerationen. A100 ist in Versionen mit 40 GB und 80 GB Arbeitsspeicher erhältlich.

Für alle Workloads geeignet
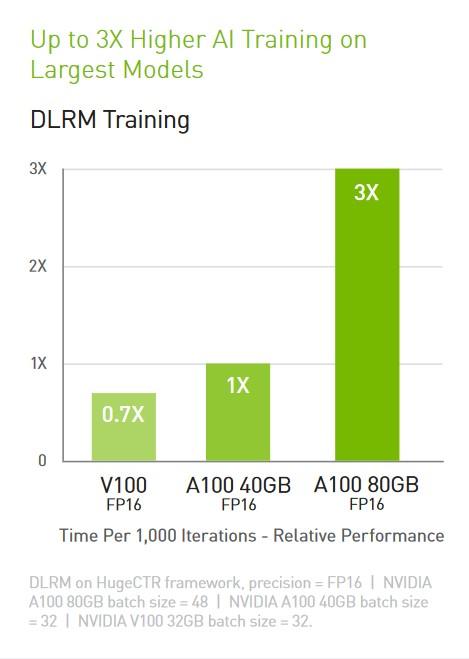
Deep Learning Training
Die Komplexität von KI-Modellen steigt rapide - somit auch der Anspruch an Rechenleistung.
Die Tensor Cores NVIDIA A100 mit Tensor Float (TF32)-Präzision bieten bis zu 20-mal mehr Leistung gegenüber NVIDIA Volta, erfordern dafür keine Code-Änderungen und bieten einen zusätzlichen 2-fachen Boost mit automatischer gemischter Präzision und FP16. Bei den größten Modelle mit massiven Datentabellen wie Deep Learning-Empfehlungsmodellen (DLRM) erreicht die A100 80 GB bis zu 1,3 TB vereinheitlichten Arbeitsspeicher pro Knoten und bietet bis zu 3-mal mehr Durchsatz als die A100 40 GB.
Inferenz für Deep Learning
Mit der A100 werden bahnbrechende Funktionen zur Optimierung von Inferenzworkloads eingeführt. Durch die Mehr-Instanzen-Grafikprozessor-Technologie (MIG) können mehrere Netzwerke gleichzeitig auf einer einzelnen A100-GPU ausgeführt werden, um die Rechenressourcen optimal zu nutzen. Zusätzlich zu den anderen Inferenzleistungssteigerungen der A100 bietet die strukturelle geringe Dichte bis zu 2-mal mehr Leistung.
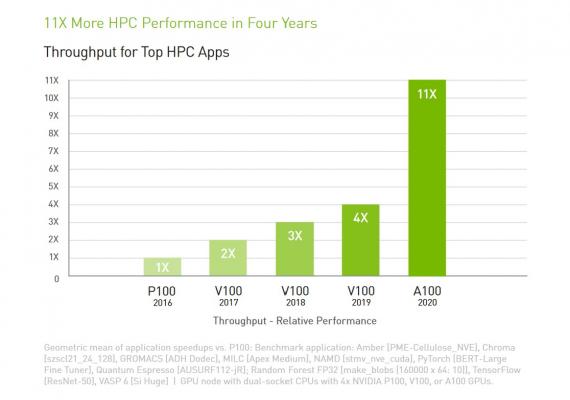
High-Performance Computing
Spitzenleistung für die Simulationen und Entdeckungen von morgen.
NVIDIA A100 führt Tensor Cores mit doppelter Präzision ein und stellt somit den größten Leistungssprung für HPC seit der Einführung von GPUs dar. In Kombination mit 80 GB des schnellsten Grafikspeichers können Forscher eine vormals 10-stündige, Simulation auf A100 mit doppelter Präzision auf weniger als vier Stunden verkürzen.
Leistungsstarke Datenanalyse
Das analysieren und visualisieren von Datensätzen kann durch bisherige Skalierungslösungen, die auf mehreren Servern aufbauen, ausgebremst werden. Die mit A100 beschleunigten Server liefern die nötige Rechenleistung in Form von Arbeitsspeicher, Speicherbandbreite und weiterer Skalierbarkeit. In einem großen Datenanalyse-Benchmark erzielte die A100 80 GB mit 83-mal höherem Durchsatz Erkenntnisse als CPUs und 2-fach höhere Leistung als die A100 40 GB, womit sie ideal für zunehmende Workloads mit stetig wachsenden Datensätzen ist.
Ihre Vorteile
Sie haben Fragen?
Falls Sie mehr zu diesem Thema erfahren möchten, freue ich mich über Ihre Kontaktaufnahme.
Zum Kontaktformular
